I read this journal article online written by Brandon C. Boatwright. It can be found here: https://journals.sagepub.com/doi/full/10.1177/21674795231196429.
In today’s world, where nearly everyone scrolls through Instagram, posts on TikTok, or watches highlight reels on YouTube, it’s easy to forget just how much data we’re leaving behind. Every like, share, comment, or hashtag contributes to what experts call “Big Data”. When researchers look at all the online info to learn how we connect, especially in sports, computational media comes into play.
Importance in Sports
Sports are a part of global culture. They bring everyone together to discuss and thanks to social media, opinions on sports are louder and heard by more. Boatwright, a sports communication scholar, argued that we instead of reading online tweets and conducting fan interviews is not enough. Sports researchers are embracing Computation Social Science (a way of studying people using tech-powered data sets) to learn more about the interaction between social media and sports.
Computational Social Science
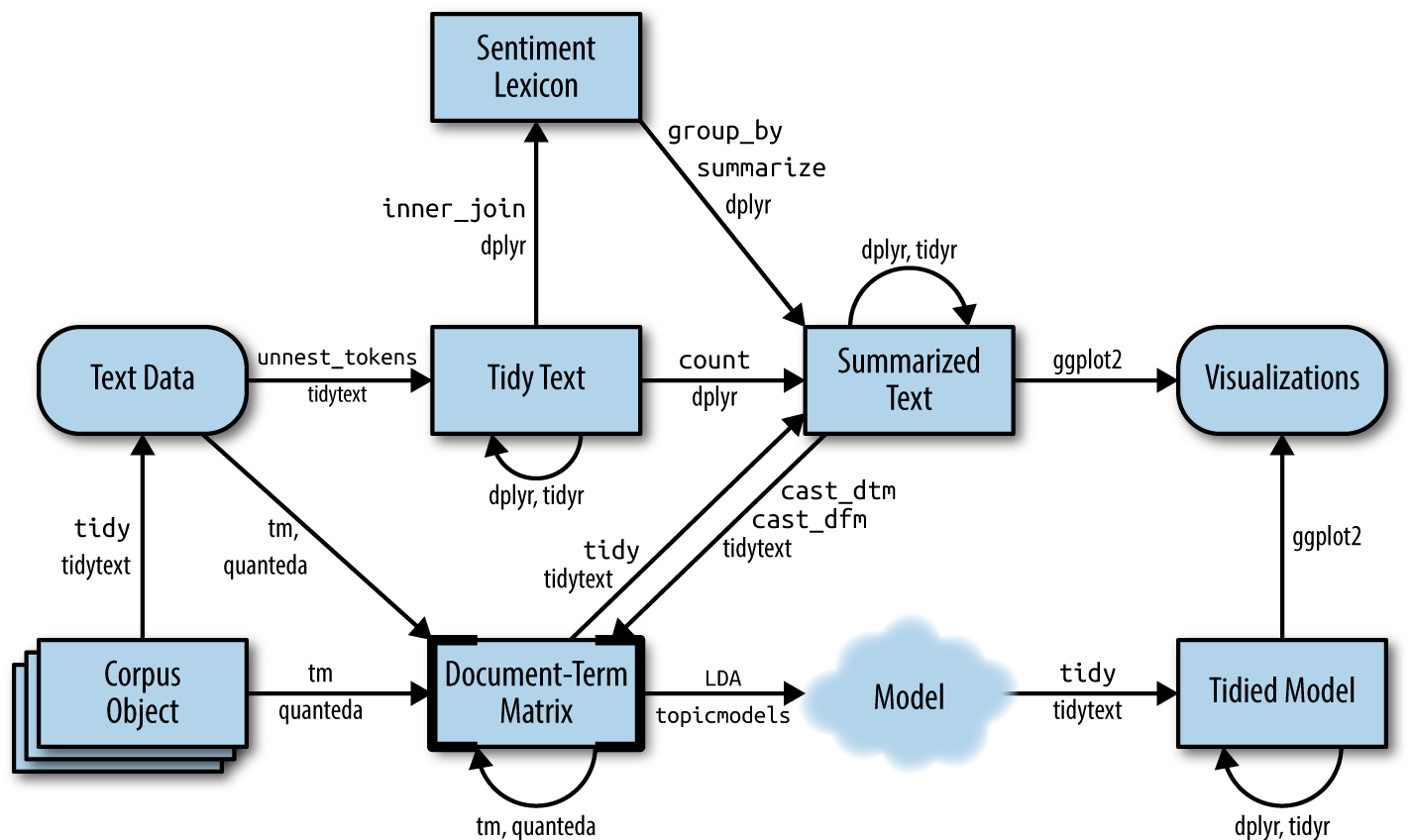
Computational Social Science (or CSS for short) is the use of computers and statistics too study human behavior. The human behavior that Boatwright is exploring in his article is the interaction on social media posts regarding sports topics. An example from the article:
“With a particular focus on social media, Kumble et al. (2022) applied LDA on 11,800 Twitter replies to Naomi Osaka’s original tweet announcing her withdrawal from the French Open in 2021. The authors identified five topics of salience among the replies, including (1) tweets that applauded and respected Osaka for her decision, (2) encouraged Osaka to prioritize her health, (3) blamed external factors (i.e., the structure of the event, the organizers, and journalists) for Osaka’s withdrawal, (4) expressed anticipation to see Osaka [eventually] compete again, and (5) sought to destigmatize mental health through visibility. LDA allowed the researchers to analyze the entire corpus of replies to identify the optimal number of topics within the dataset by measuring the semantic similarity (i.e., Cv coherence value; see Roder et al., 2015) between topic-related words, rather than drawing from a random sample and relying on human coders to identify topics manually.” – Boatwright
For this study, CSS was used to analyze the tweets and opinions replying to Naomi Osaka’s withdrawal from the French Open. “Latent Dirichlet Allocation” (LDA) is the most common form of Topic Modeling. Topic modeling is a way for computers to find common themes or topics in a large group of texts, like tweets or comments. It looks for patterns in the words people use and groups similar ones together. LDA helps show what people are talking about the most.
Challenges?
Collecting and analyzing data sounds really efficient and useful, but what are some of the challenges associated with CSS?
The first concern is privacy. Is it alright to study people’s responses online, even if it is already public. Their words can be used for datasets without their consent.
Another thing that could come up is the natural bias of the data coming from the platform. Not every social media platform displays the comments/replies the same way, there could be some censoring or differing algorithms that could skew the data.
The last challenge is that this is not easily doable by anyone. A certain degree of knowledge is required, such as a basic understanding of coding, algorithms, and statistics.
